HackerFlix: A Work In Progress

Intro⌗
Today I’m excited to share my latest development project: HackerFlix.net!
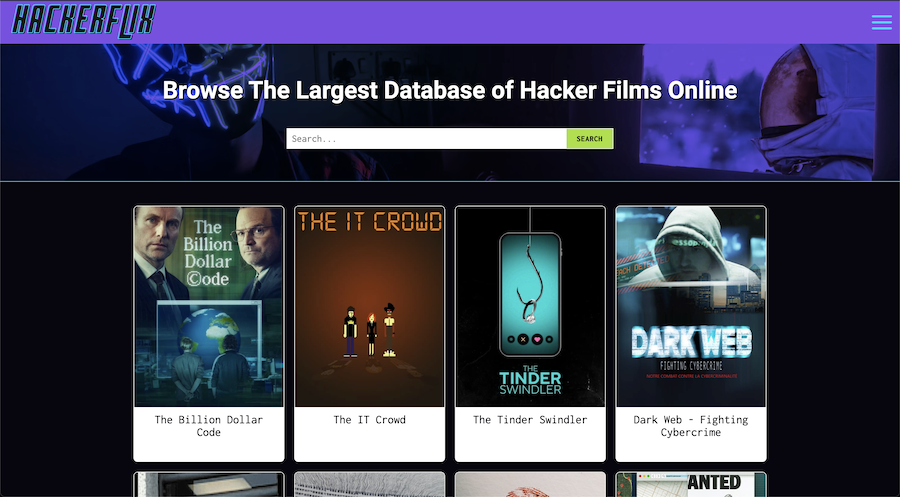
HackerFlix is a curated directory of documentaries, docuseries, movies, and tv shows about computers, hacking, technology, privacy, cyberpunk and Internet culture.
It includes many well known Hollywood productions and even more lesser known documentaries and docuseries within the tech genre.
While I have compiled the list on my own, the data and imagery is almost all supplied by The Movie DB via their public API.
This is a project I’ve wanted to build for a while now. I love watching tech documentaries and have seen many films and shows featured on the site already. It was also partially inspired by this post on r/hacking where someone asked for hacking documentary recommendations.
And finally from a practical standpoint, I needed a new portfolio project, and this was a great fit in terms of size and complexity. Thus, HackerFlix was born!
Architecture⌗
HackerFlix is a full stack javascript application. The backend is written in NodeJS using the Express web framework.
It uses the EJS view engine for templating, as well as modern vanilla javascript on the frontend. Styles are written in SCSS. Carousels are powered by GlideJS.
(Other tooling includes Babel for transpilation, Prettier for formatting, and Webpack for bundling.)
Since the majority of the data comes from the TMDB API, the application does not require its own database.
For the little bit of data I do have (classification, slugs, and tags for each item), a Google Sheet proves sufficient and makes maintaining the data easy. There’s no need to custom build or spin up a CMS, content updates do not require code updates, and it even supports multiple “environments” via tabs.
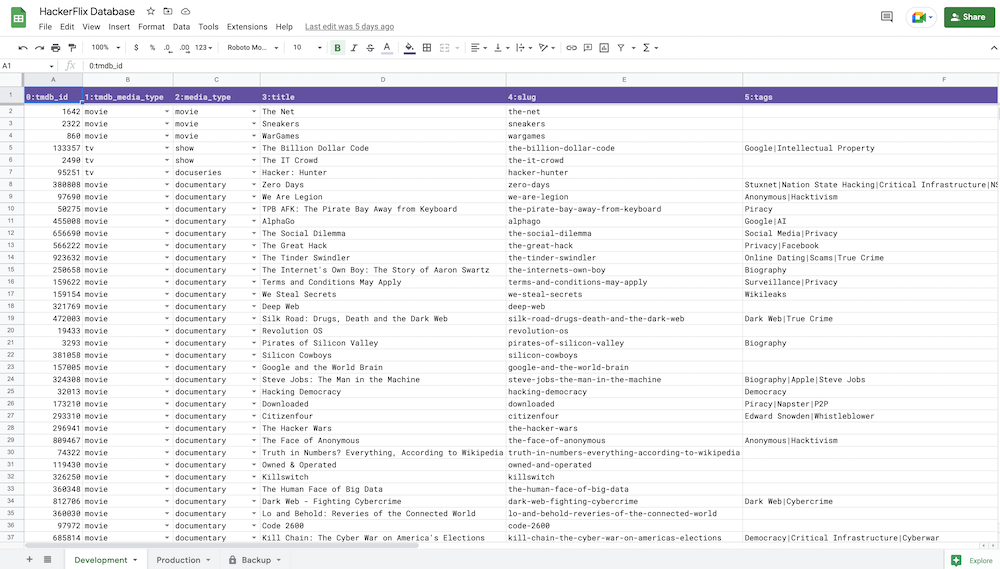
In the application’s bootstrap process, all the data from TMDB and the Google Sheet are fetched and run through ETLs to transform and load the combined dataset into a Redis cache.
Only the data needed to render the homepage is cached at first. As specific film/show pages are requested, additional details are fetched and loaded into the cache as well to avoid hitting the TMDB API on every single request.
Additionally, with the initial set of features I planned for the first version of the site, 99% or more of data operations are reads, so Redis made more sense over a RDBMS.
I am using redis-om which provides search capabilities and the ability to interact with the cache using an object model much like an ORM for a database. (Redis OM has its limitations, but is good enough for now.)
Lesson Learned⌗
There are several more ideas for improvements I have, many of which I had intended to build before launching.
I will continue building new features over time, but over the past week or so I realized the site in its current state is good enough. I was starting to get burned out and feeling torn between further development or getting back to hacking on CTFs and other projects.
So, rather than waiting for a “perfect” site, I’m launching this as what it is: a work in progress.
Final Thoughts⌗
HackerFlix is open source. Soon I will move the backlog from my private Notion into GitHub, and I welcome any I welcome any suggestions, enhancements, and/or bug fixes!
I’d also appreciate any content recommendations At the moment, only films and shows available on TMDB can be shown. (Special thanks to TMDB for sharing their data!)